常见问题
不能登录到集群的管理节点?¶
首先请检查自己的网络环境是否正常,登录到集群管理节点的IP地址、用户名和密码是否正确。相同网络环境,其他的账号是否能正常登陆。如果多次检查后仍无法登录,请联系管理员解决。
ssh能登录,但FTP客户端不能连接?¶
填写FTP客户端时同样需检查IP地址、用户名和密码,此外协议类型必须选择SFTP而不是默认的FTP。
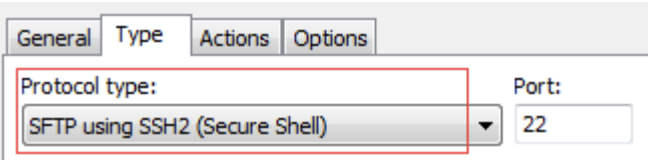
如果这些都检查正确还是不能正常的连接,请检查以前是否安装的有低版本的FTP客户端而没有卸载干净还保留了其配置文件,这时请卸载删除干净后再安装高版本的FTP客户端,或者换一种其他的FTP客户端使用。
如何修改登录密码?¶
用户得到登录帐号和初始密码后应及时修改。可以使用passwd命令后回车直接修改,先输入原密码,再输入两次新密码。需要注意的是,linux下密码是不会像windows下那样回显,你键盘输入完后回车就行,不必担心自己没输入上密码。输入新密码时不要过于简单,基于用户名和英文单词的密码不被系统接受。

登录时为什么会出现这种情况-bash-4.1$¶
出现这种情况一般是用户使用FTP客户端时删除了.bashrc, .bash_profile, bash_logout等带点的配置文件。在linux中,这些文件是隐藏文件,但有的FTP客户端会默认显示这些文件,而用户以为不是他/她自己建立的文件,就给删除了。用ssh客服端登录管理节点,使用以下命令恢复:
cp /etc/skel/.bashrc ~/
cp /etc/skel/.bash_profile ~/
cp /etc/skel/.bash_logout ~/
如何知道用户自己的核数资源限制?¶
可使用show_limits命令查看资源限制:
[userA@quantum ~]$ show_limits
Account User GrpCPUs CPU_Use
---------- ---------- -------- --------
chemistry userA 100 80
如何使用Gaussian软件中的formchk和cubegen命令?¶
这里提供三种方法:
-
1)在家目录下的.bashrc文件中写上Gaussian的环境变量
[userA@quantum ~]$ vi ~/.bashrc这时按键盘i,光标调到最下面一行,添加如下两行:然后按键盘的Esc键,再输入:wq回车(注意是冒号wq后再回车),然后使用source刷新环境变量export g09root=/opt/soft/gauss/g09d01_linda source $g09root/g09/bsd/g09.profilesource ~/.bashrc这时就可以使用D01版本 Gaussian 09的formchk和cubegen命令了。
如果是Gaussian 16,在家目录的.bashrc里添加如下两行:
保存退出后,刷新环境变量export g16root=/opt/soft/gauss/g16c01_avx2 source $g16root/g16/bsd/g16.profilesource ~/.bashrc这时就可以使用C01版本Gaussian 16的formchk和cubegen命令了。
注意
在.bashrc里不能同时添加Gaussian 09和Gaussian 16的环境变量。
-
2)使用module命令加载程序的环境变量
查看有哪些程序软件可以使用module,
可使用module的有列出软件的各个版本的程序以及intel编译器。加载D01版本的Gaussian 09变量:[userA@quantum ~]$ module av ------------------------ /usr/share/Modules/modulefiles ------------------------- dot module-git module-info modules null use.own ------------------------ /opt/modulefiles --------------------------------------- anaconda3 gauss/g16c01 gmx/2022.5 miniconda3 cmake-3.26.3 gcc11.4.0 intel/compiler/2022.2.0 multiwfn/3.8_dev cp2k gcc13.2.0 intel/impi/2021.7.0 orca5.0.4 gauss/g09d01 gmx/2018.4 intel/mkl/2022.2.0 orca6.0.0module load gauss/g09d01这时就可以使用D01版本Gaussian 09的formchk和cubegen命令了。
如果这时想用C01版本Gaussian 16的formchk和cubegen命令,要先卸载刚才D01版本的环境变量module unload gauss/g09d01然后再module load gauss/g16c01
当然如果一开始登录就想使用C01版本Gaussian 16的formchk和cubegen,这时直接用module加载就行module load gauss/g16c01
-
3)用alias设置命令别名
在ssh客户端操作如下命令
只需要执行一次,以后再登录集群,不用再执行。echo "alias g09formchk=/opt/soft/gauss/g09d01_linda/g09/formchk" >> ~/.bashrc echo "alias g09cubegen=/opt/soft/gauss/g09d01_linda/g09/cubegen" >> ~/.bashrc echo "alias g16formchk=/opt/soft/gauss/g16c01_avx2/g16/formchk" >> ~/.bashrc echo "alias g16cubegen=/opt/soft/gauss/g16c01_avx2/g16/cubegen" >> ~/.bashrc source ~/.bashrc
在当前目录下有Gaussian 09计算的g09test.chk和Gaussian 16计算的g16test.chk,想把这两个chk文件转化为fchk文件,执行如下命令
如果总是使用一个版本的Gaussian计算,推荐用第一种方法;如果有几个体系,而这几个体系用的Gaussian版本不一样,建议使用第三种方法;如果module命令用的比较熟悉,优先推荐使用第二种方法。g09formchk g09test.chk g16formchk g16test.chk
同样,要使用ORCA不同版本的orca_2mkl这些后处理脚本也是与上述Gaussian一样的处理方法。
在使用formchk时出现Out-of-memory error,怎么办?¶
在使用formchk命令时,如果chk文件特别大,需要耗费更大的内存,容易出现如下错误
[userA@quantum td] g16frmchk 1-FeH-b3-d3-td.chk
Read checkpoint file 1-FeH-b3-d3-td.chk type G16
Write formatted file 1-FeH-b3-d3-td.chk
FChkPn: Coordinates translated and rotated.
FChkPn: Coordinates match /B/ after translation and rotation.
Out-of-memory error in routine WrCIDn-1 (IEnd= 383861501 MxCore= 104857339)
Use %mem=367MW to provide the minimum amount of memory required to complete this step.
Error termination via Lnk1e at Thu Dec 10 10:38:33 2020.
Error: segmentation violation
export GAUSS_MEMDEF=4GB
formchk xxx.chk
为什么作业一直处于PD排队等候状态?¶
首先,提交的作业由Slurm作业管理系统智能分配资源,一分钟之内处于PD状态正常。超过一分钟,作业处于PD状态,那就确定是在排队。
其次,确定排队后,那就看是否是资源限制的问题。资源限制使用show_limits命令查看,具体的分析看手册管理和监控作业状态部分的show_limits命令查看资源限制。
最后,如果确定自己和组都有资源,但还是排队。这种情况下使用pestat命令查看节点的情况。如果提交的是12核作业,而每个节点只有8核和4核的空余,这种情况的确会排队。对于MPI运行的软件,这种情况使用自定义脚本提交,用"-N2 -n12"参数提交,不会排队。但我们使用的Gaussian 16不带linda,会排队。
为什么同一个作业每次提交后过一段时间就死掉了?¶
首先查看计算的结果文件,确认是程序还是作业系统杀掉的。如果是计算程序,比如Gaussian 16,结果文件中会出现Error或Not normal termination之类,这种情况就是输入文件的情况了。如果是Slurm作业系统杀掉的,那一般是提交作业申请的资源(主要是内存)超过了作业系统基于物理内存设置的限制,或者产生的临时文件占用满了了计算节点的根目录存储空间导致节点STATE状态为drain状态,从而被杀掉。
那么如何知道这个被杀掉的作业所需要的最大内存呢?假如这个作业名是test,计算完之后会出现test.o66236,那么作业JOBID是66236。可以使用sacct-all 66236命令查看作业所使用的最大内存,输出的第94行TRESUsageInTot查看mem和vmem值,是否超过了节点物理内存的95%,如果超过就被杀掉了。这种情况下,最好使用大内存节点计算。
除了内存使用问题,还有硬盘存储的问题。使用sacct-all JOBID查看Nodelist一行,来确定死掉的作业在哪个计算节点计算的。假如是cu46节点,我们这时使用ssh cu46命令进入此节点,然后再使用df -hl查看"/"根目录的使用情况,如果根目录Use%值超过了80%或90%,那么重新提交的作业很可能由于硬盘存储不够而死掉。用户可以cd /tmp后,再执行du -sh *查看是同组哪个用户造成临时文件大了造成磁盘空间不足,再告知他/她进入该节点,删除/tmp下的数据(假如是/tmp下userA的数据大,那么userA先ssh cu46再rm -rf /tmp/userA删除数据)。或者等晚上凌晨系统脚本自动清理掉死掉作业的临时文件数据,实在着急时也可联系管理员帮忙处理。
本站总访问量 次