IB存储部署踩坑记录
硬件采购¶
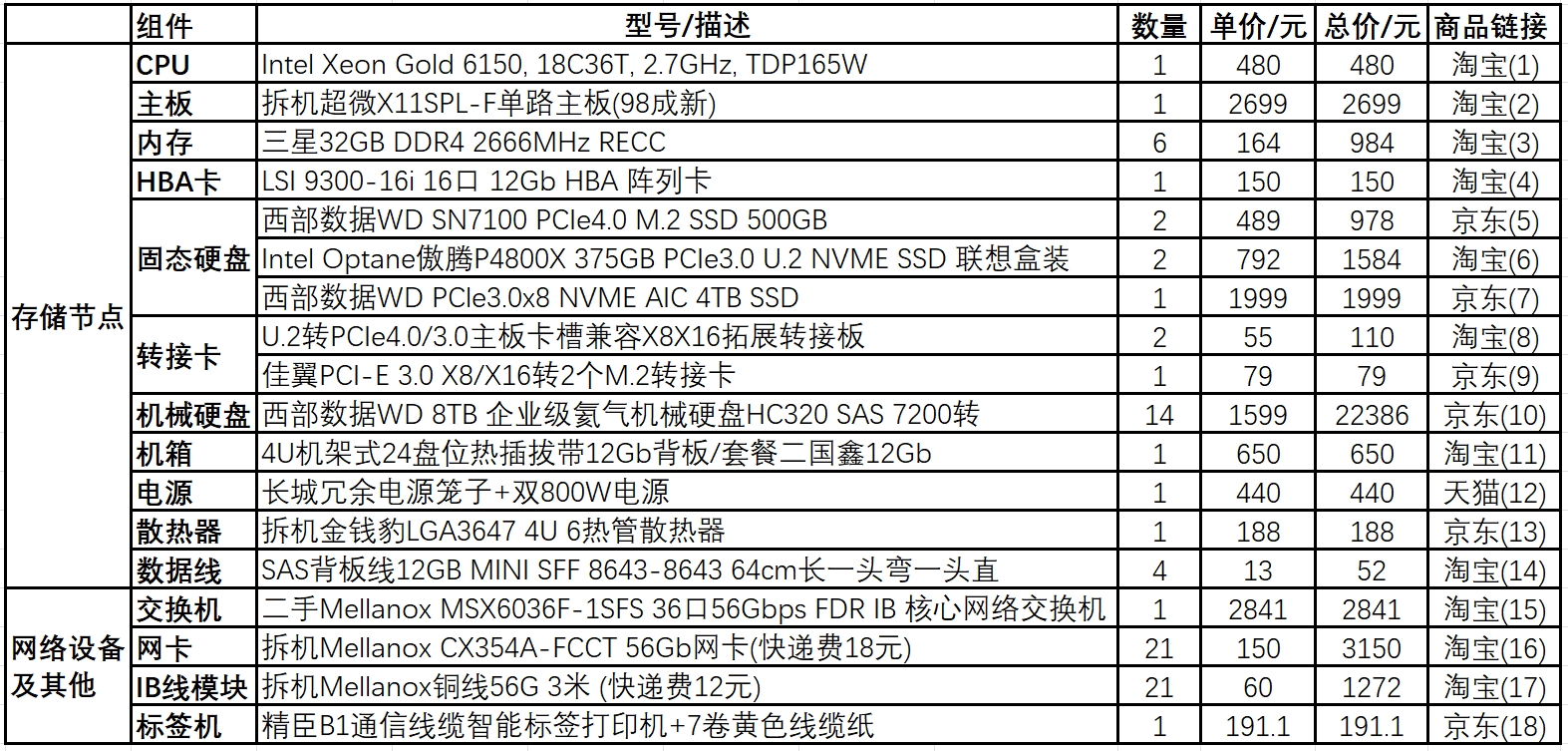 商品链接: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
商品链接: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
表格中商品链接价格受市场行情有较大变化,仅供参考,具体货源及价格情况都需要再次向店家询问确认才行。
上面的二手散件主要借鉴了科音论坛Entropy.S.I发表的DIY NAS小记 | Mini高性能集群部署,但是拆机40G/56G InfiniBand散件已经与光纤万兆网络散件的价格差不多,因而使用InfiniBand网络。
这些散件单独购买,学校也能报销,但购买、报销流程繁琐,且硬件售后麻烦,所以就找本地销售商代为购买和售后。尽管价格成本会增加些,但价格公道和售后服务质量是值得的。
InfiniBand网络调试¶
交换机调试¶
由于是买的二手Mellanox MSX6036F交换机,客服技术人员说是调试了好用,但也得亲自确认下。还有我们需要交换机所有网口都是IB模式协议,如果有ETH模式,也需要切换过来。 调试过程可以参考CSDN博客
注意
- 调试前需要准备1根串口USB转RJ45的Console线,如果没有,可在淘宝购买。RJ45接交换机Console口,串口USB接Windows电脑。
- 在Windows电脑设备管理器中确认【端口(COM和LPT) → USB-SERIAL CH340 (COM几)】串口名字,然后在Putty中的Connection type选择Serial,Serial line填写Windows设备管理器中出现的COM几,Speed里一般填写9600或115200。
- Putty填写完,点击Open连接时,这时Putty界面只显示一个光标闪烁,需要点击键盘回车或空格键就能出现登陆信息。账户和密码均为admin。
-
查看所有端口的状态和模式:
show interfaces -
切换端口模式
保存配置后,可再用enable configure terminal interface <port_number> # ib/eth分别表示端口为InfiniBand模式和Ethernet模式 switchport mode ib/eth # 保存配置 write memoryshow interfaces验证端口状态和模式。 -
启用web模式
管理口接网线,如果是DHCP自动获取IP,那就用enable configure terminal web enableshow ip interface查看管理口IP。也可用ip命令给管理口设置IP,然后与Windows电脑组成局域网就行。在Windows电脑浏览器中输入http://ip, 也可能是https,都可试试。账号密码与console的一样,均为admin。
Mellanox卡设置¶
-
安装mstflint工具
yum install mstflint -
给网卡刷新固件版本 在Nvidia官网下载相应网卡版本固件。
列出Mellanox网卡PCI总线地址其中31:00.0就是Mellanox CX354A-FCCT网卡在cu17节点的PCI总线地址。[root@cu17 ~]# lspci |grep -i mellanox 31:00.0 Network controller: Mellanox Technologies MT27520 Family [ConnectX-3 Pro]
刷入下载的固件刷入固件后,需要重启机器,才能加载网卡的新固件版本。# 获得固件信息 mstflint -d 31:00.0 query # 刷入固件 mstflint -d 31:00.0 -i fw-ConnectX3Pro-rel-2_42_5000-MCX354A-FCC_Ax-FlexBoot-3.4.752.bin burn -
设置IB卡端口模式
查看当前网卡模式ibstat命令可查看网卡模式,这里主要看"Link layer"。[root@cu17 ~]# ibstat CA 'mlx4_0' CA type: MT4103 Number of ports: 2 Firmware version: 2.38.5000 Hardware version: 0 Node GUID: 0x043f7203000ce330 System image GUID: 0x043f7203000ce333 Port 1: State: Active Physical state: LinkUp Rate: 56 Base lid: 21 LMC: 0 SM lid: 1 Capability mask: 0x02594868 Port GUID: 0x043f7203000ce331 Link layer: InfiniBand Port 2: State: Down Physical state: Disabled Rate: 10 Base lid: 0 LMC: 0 SM lid: 0 Capability mask: 0x00010000 Port GUID: 0x063f72fffe0ce332 Link layer: Ethernet
也可以用mstconf命令查看当前网卡模式。[root@cu17 ~]# mstconfig -d 31:00.0 query |grep LINK_TYPE LINK_TYPE_P1 IB(1) LINK_TYPE_P2 ETH(2)- IB(1) 通常表示只支持InfiniBand
- ETH(2) 通常表示只支持Ethernet
- VPI(3) 意味着该端口同时支持InfiniBand和Ethernet
更改网卡端口模式
这里cu17节点IB卡的第2个端口是Ethernet,我们把其改为InfiniBand模式修改后,需要重启机器才能生效。[root@cu17 ~]# mstconfig -d 31:00.0 set LINK_TYPE_P2=1 - IB(1) 通常表示只支持InfiniBand
OpenSM安装与运行¶
OpenSM是InfiniBand网络中的一个关键组件,负责管理和配置InfiniBand子网,分配和维护IB设备的GUID(全局唯一标识符),并为InfiniBand网络的连接提供路由信息。
当时Windows Server机器是驱动IB卡了的,连接到Mellanox MSX6036F交换机,但其连接的交换机网口是亮红灯的。之前已确认Mellanox网卡和交换机端口是InfiniBand模式,因此缺少运行的OpenSM。OpenSM必须在至少一个节点上运行,通常在交换机上运行,或者在某些情况下,也可以在IB卡所在的计算节点上运行。但目前IB交换机并没有运行OpenSM,可能是没配置好。那我们就在IB卡所在的计算节点上安装。
-
Windows安装并运行OpenSM
下载适用于Windows的驱动程序包(通常称为 "WinOF" 或 "WinOF-2",通常会包含OpenSM的组件), ConnectX-3或ConnectX-3 Pro下载WinOF。安装完后,重启系统。打开CMD命令提示符,输入opensm命令后回车即可。 -
RHEL/Rocky Linux安装并运行OpenSM
yum install opensm -y systemctl enable --now opensm
安装运行OpenSM后,过一会后,IB线连接的交换机网口灯就变绿了。
TrueNAS Scale安装¶
TrueNAS Scale使用的OpenZFS文件系统为存储系统提供了可靠性和数据保护功能,包括:快照、数据压缩、数据去重、写时复制(COW)、RAID-Z等功能。这使得TrueNAS Scale具备很高的数据完整性和恢复能力。
TrueNAS Scale安装和操作几乎都是图形化,简单易操作。
注意
- 制作U盘启动,最好用Rufuse把TrueNAS Scale iso刻录到U盘;用Ventoy启动TrueNAS Scale 24.10.1 iso镜像文件,当时没好使。
- 修改静态IP: 左侧面板菜单的网络→编辑相应网口→在编辑接口去掉DHCP并在别名处点击添加,这样可以添加静态IP和子网页码。
NFS over RDMA¶
TrueNAS Scale 24.10版本图形界面还不支持NFS over RDMA,25.04将支持。
在/etc/modules里加入这三个模块确保开机启动
ib_ipoib
ib_umad
svcrdma
rdma=y
rdma-port=20049
LDAP接入¶
这里是接入LDAP,不是在TrueNAS Scale部署LDAP server。
左侧面板菜单的用户凭证→目录服务→LDAP,点击设置:
主机名: LDAP server的IP
基本 DN: dc=hpc,dc=com
绑定 DN: cn=Manager,dc=hpc,dc=com
绑定密码: LDAP server的密码
NFS共享和挂载¶
假如建的存储池为datapool,数据集为存储池下的home。点击左侧面板菜单的共享,NFS共享添加路径为/mnt/datapool/home; 点击NFS共享里的配置服务,已启用协议选择NFSv3,NFSv4。最后开启NFS共享服务。
# showmount命令查看共享目录
root@truenas[~]# showmount -e localhost
Export list for localhost:
/mnt/datapool/home *
# 奇怪的是,挂载共享路径下的子文件夹挂载不成功
[root@quantum home]# mount.nfs4 truenas:/mnt/datapool/home/userA /home/userA
mount.nfs4: access denied by server while mounting truenas:/mnt/datapool/home/userA
# 在同网段局域网机器使用mount挂载
[root@quantum ~]# mount.nfs4 truenas:/mnt/datapool/home/ /home/
[root@quantum ~]# df -h |grep home
truenas:/mnt/datapool/home 55G 512K 55G 1% /home
OpenZFS的操作和管理¶
TrueNAS Scale有直观的图形界面操作,且官方推荐使用图形操作。有的情况个人需要开启apt安装一些软件,但这样对TrueNAS这系统和图形界面可能造成潜在的稳定性或安全风险。这种情况,建议还是使用Ubuntu等系统安装OpenZFS。
# 创建 RAIDZ2(类似 RAID6)
zpool create datapool raidz2 /dev/sda /dev/sdb /dev/sdc /dev/sdd /dev/sde /dev/sdf /dev/sdg /dev/sdh
# 上面命令中raidz2被替换为: raidz类似raid5, mirror类似raid1, 去掉raidz2就类似raid0
# 查看存储池状态
zpool status
zpool list
# 添加新磁盘到池
zpool add datapool /dev/sdi
# 替换故障磁盘
zpool offline datapool /dev/sdb # 离线故障盘
zpool replace datapool /dev/sdb /dev/sdi # 替换为新盘(如/dev/sdi)
# 销毁存储池
zpool destroy datapool
# 创建数据集(Dataset)
zfs create datapool/dataset1
zfs create -o compression=lz4 datapool/dataset2 # 创建并启用压缩
# 如果创建数据集时没有启用压缩,也可以之后设置压缩
zfs set compression=lz4 datapool/dataset1 # 启用压缩
zfs set compression=off datapool/dataset1 # 禁用压缩
# 挂载与卸载数据集
zfs set mountpoint=/path/to/mount datapool/dataset1
zfs mount datapool/dataset1
zfs unmount datapool/dataset1
# 添加缓存(L2ARC)
zpool add datapool cache /dev/nvme1n1
# 添加日志(ZIL,现在多称为SLog),此设备容量仅需承载5-30秒的同步写入峰值,最终数据仍写入主存储。
# 因此就算日志设备出问题,也就是1分钟内的数据受影响。因此建不建立raid1,没啥大的影响。
# 若同步写入峰值持续数分钟,需按实际带宽计算(如 10,000MB/s × 60秒 = 600GB → 选 1TB SSD即可)。
zpool add datapool log mirror /dev/nvme2n1 /dev/nvme3n1
磁盘阵列RAID¶
RAID(Redundant Array of Independent Disks) 是一种将多个物理硬盘组合成一个逻辑硬盘阵列的技术。RAID旨在提高存储系统的性能、冗余性(数据保护)和容量利用率。不同的RAID级别适用于不同的需求,RAID 0适合追求高性能的场景,RAID 1适合需要高数据冗余的场景,而RAID 5和RAID 6则在性能和冗余之间提供了更好的平衡。
常见的RAID级别¶
-
RAID 0(条带化)
无冗余,所有空间可用(数据分散到多个硬盘,提升了数据的读写速度)。如果其中任何一个硬盘损坏,所有数据都会丢失。
适用场景:需要高性能而不关心数据冗余的情况,如视频编辑、游戏等。 -
RAID 1(镜像)
数据冗余(若一个硬盘故障,另一个硬盘的数据仍然完好),容量减半,读取性能提升(两个硬盘可以同时提供数据)。
适用场景:需要高度数据保护的场景,如系统、个人重要数据存储。 -
RAID 5(条带化+奇偶校验)
数据冗余,性能较好,读取性能接近RAID 0,写入性能稍低(由于奇偶校验的计算)。存储空间利用率较高,至少需要三个硬盘(能够容忍一个硬盘的故障)。
适用场景:需要较高性能和冗余的应用,如文件服务器、大型数据库等。 -
RAID 6(条带化+双奇偶校验)
与RAID 5类似,至少需要四个硬盘,存储空间利用率较RAID 5稍低,写入性能也较低;但有两个奇偶校验块,因此可以容忍两个硬盘同时故障。
适用场景:需要极高数据冗余的场景,如企业级存储、备份服务器等。 -
RAID 10(1+0,镜像+条带化)
结合RAID 1和RAID 0特点,提供很高的性能和数据冗余(可容忍多个硬盘故障只要其中RAID 1中的一组硬盘没问题就行)。存储空间利用率较低,至少需要四个硬盘,且只有一半空间可用。
适用场景:需要高性能和高冗余的场景,如数据库服务器、虚拟化平台等。
目前这个IB存储,部署的是2个傲腾硬盘组RAID 0(软RAID),14块SAS盘用RAID阵列卡建了2组RAID 5。
软RAID建立¶
- 安装mdadm工具
yum install -y mdadm - 创建分区并标记为RAID类型
parted /dev/nvme2n1 mklabel gpt parted /dev/nvme2n1 mkpart primary 0% 100% parted /dev/nvme2n1 set 1 raid on # 第一个分区标记为RAID分区 parted /dev/nvme3n1 mklabel gpt parted /dev/nvme3n1 mkpart primary 0% 100% parted /dev/nvme3n1 set 1 raid on # 第一个分区标记为RAID分区 - 创建RAID 0
mdadm --create --verbose /dev/md0 --level=0 --raid-devices=2 /dev/nvme2n1p1 /dev/nvme3n1p1 # /dev/md0:新创建的RAID设备名称。 # --level=0:RAID级别(可选RAID0、RAID1、RAID5、RAID6等)。 # --raid-devices=2:使用的磁盘数量。 - 查看RAID状态
mdadm --detail /dev/md0 # 或 cat /proc/mdstat - 格式化并挂载RAID阵列
配置开机自动挂载: 编辑/etc/fstab,添加如下内容
mkfs.xfs -f /dev/md0 mount /dev/md0 /opt/fastcfs/fdir/保存当前RAID配置以便开机加载:/dev/md0 /opt/fastcfs/fdir xfs defaults 0 0mdadm --detail --scan >> /etc/mdadm.conf
软RAID监控和维护¶
- 查看RAID状态
mdadm --detail /dev/md0 # 或 cat /proc/mdstat - 模拟磁盘故障并替换
RAID 0损坏了,数据全丢失;其他的RAID级别,有冗余可替换# 标记磁盘为故障 mdadm /dev/md0 --fail /dev/sdb1 # 移除故障磁盘 mdadm /dev/md0 --remove /dev/sdb1 # 添加新磁盘 mdadm /dev/md0 --add /dev/sde1 - 扩展RAID
# 添加新磁盘到RAID mdadm --add /dev/md0 /dev/sde1 # 扩展RAID阵列 mdadm --grow /dev/md0 --raid-devices=4
结合smartctl工具定期监控磁盘健康,输出解释可查看前面写的命令行查询硬件参数。
硬RAID监控和管理¶
软RAID是通过操作系统的内核来实现的,通常使用软件工具来配置和管理RAID阵列。硬RAID是通过专门的硬件控制卡(RAID卡)来实现的,由于其控制器有独立的缓存和处理能力,能够加速数据传输和处理速度。目前我们使用LSI MR9362-8i 1G缓存为14块SAS盘用建立2组RAID 5。
-
在主板BIOS中进行阵列操作
开机Delete进入BIOS → Advance → AVAGO MegaRAID Configuration Utility → Main Menu → Configuration Management → Create Virtual Drive → Select RAID Level中选择RAID5 (同样是Select RAID Level这一页,对于RAID5以上级别,Write Policy后选择"Always Write Back") → Select Drives中选择前7块硬盘(将disable改为enable即为选中,选中后在Apply Changes回车下) → Save Configuration中点击yes。
直观的图形界面操作,可以参看浪潮英信服务器在BIOS中配置RAID 5的方法。
另一组RAID 5同样操作就行。 -
安装管理工具
# 安装SMART工具,系统默认是安装了的 yum install smartmontools # 安装LSI MegaCLI/StorCLI,storcli是新一代工具,推荐使用 # 在https://www.broadcom.com/中搜索并下载STORCLI_SAS3.5,解压出rpm包 rpm -ivh storcli-007.3205.0000.0000-1.noarch.rpm -
检查RAID阵列状态
RAID5正常State为Optl, 每块盘正常State为Onln。# 查看RAID卡和阵列摘要 /opt/MegaRAID/storcli/storcli64 /c0 show # /c0 表示第一个RAID控制器; show后也可加all列出更详细参数 # 查看物理硬盘状态 /opt/MegaRAID/storcli/storcli64 /c0 /eall /sall show all # 列出所有物理硬盘Media Error: 错误计数应为 0 ; Predictive Failure: 预测性故障应为 No.# 检查错误计数和预测性故障 /opt/MegaRAID/storcli/storcli64 /c0 /eall /sall show all |egrep 'Error|Predictive Failure' -
监控硬盘SMART数据
smartctl --scan扫描硬盘megaraid_disk_21代表硬盘槽位号为21,但是这个硬盘到底对应哪组RAID5中的哪个硬盘呢?[root@ibnas ~]# smartctl --scan |grep raid /dev/bus/8 -d megaraid,21 # /dev/bus/8 [megaraid_disk_21], SCSI device /dev/bus/8 -d megaraid,22 # /dev/bus/8 [megaraid_disk_22], SCSI device /dev/bus/8 -d megaraid,23 # /dev/bus/8 [megaraid_disk_23], SCSI device /dev/bus/8 -d megaraid,24 # /dev/bus/8 [megaraid_disk_24], SCSI device /dev/bus/8 -d megaraid,25 # /dev/bus/8 [megaraid_disk_25], SCSI device /dev/bus/8 -d megaraid,26 # /dev/bus/8 [megaraid_disk_26], SCSI device /dev/bus/8 -d megaraid,27 # /dev/bus/8 [megaraid_disk_27], SCSI device /dev/bus/8 -d megaraid,28 # /dev/bus/8 [megaraid_disk_28], SCSI device /dev/bus/8 -d megaraid,29 # /dev/bus/8 [megaraid_disk_29], SCSI device /dev/bus/8 -d megaraid,30 # /dev/bus/8 [megaraid_disk_30], SCSI device /dev/bus/8 -d megaraid,31 # /dev/bus/8 [megaraid_disk_31], SCSI device /dev/bus/8 -d megaraid,32 # /dev/bus/8 [megaraid_disk_32], SCSI device /dev/bus/8 -d megaraid,33 # /dev/bus/8 [megaraid_disk_33], SCSI device /dev/bus/8 -d megaraid,34 # /dev/bus/8 [megaraid_disk_34], SCSI device # 抓取关于扫描的raid硬盘设备,megaraid_disk_21到megaraid_disk_34共14个硬盘
使用/opt/MegaRAID/storcli/storcli64 /c0 show输出阵列和硬盘的拓扑。从拓扑表格可看出DID(Device ID)是21-34,对应TOPOLOGY : ======== ---------------------------------------------------------------------------- DG Arr Row EID:Slot DID Type State BT Size PDC PI SED DS3 FSpace TR ---------------------------------------------------------------------------- 0 - - - - RAID5 Optl N 43.661 TB dsbl N N none N N 0 0 - - - RAID5 Optl N 43.661 TB dsbl N N none N N 0 0 0 20:1 23 DRIVE Onln Y 7.276 TB dsbl N N none - N 0 0 1 20:3 24 DRIVE Onln Y 7.276 TB dsbl N N none - N 0 0 2 20:5 28 DRIVE Onln Y 7.276 TB dsbl N N none - N 0 0 3 20:0 29 DRIVE Onln Y 7.276 TB dsbl N N none - N 0 0 4 20:4 30 DRIVE Onln Y 7.276 TB dsbl N N none - N 0 0 5 20:6 32 DRIVE Onln Y 7.276 TB dsbl N N none - N 0 0 6 20:2 34 DRIVE Onln Y 7.276 TB dsbl N N none - N 1 - - - - RAID5 Optl N 43.661 TB dsbl N N none N N 1 0 - - - RAID5 Optl N 43.661 TB dsbl N N none N N 1 0 0 20:10 21 DRIVE Onln Y 7.276 TB dsbl N N none - N 1 0 1 20:13 22 DRIVE Onln Y 7.276 TB dsbl N N none - N 1 0 2 20:9 25 DRIVE Onln Y 7.276 TB dsbl N N none - N 1 0 3 20:7 26 DRIVE Onln Y 7.276 TB dsbl N N none - N 1 0 4 20:8 27 DRIVE Onln Y 7.276 TB dsbl N N none - N 1 0 5 20:12 31 DRIVE Onln Y 7.276 TB dsbl N N none - N 1 0 6 20:11 33 DRIVE Onln Y 7.276 TB dsbl N N none - N ----------------------------------------------------------------------------smartctl --scan扫描硬盘的硬盘槽位号,所以megaraid_disk_21对应DG1这一组RAID5的Row0硬盘。
此外DID:21,对应的EID:Slot为20:10,因而使用storcli对应的就是/c0/e20/s10: /c0表示第一个RAID控制器, /e20表示扩展器20,/s10表示磁盘槽位10。
这样使用/opt/MegaRAID/storcli/storcli64 /c0/e20/s10 show all可单独查看这块盘的制造商、序列号等信息,但S.M.A.R.T温度健康信息还是没有。# 直接通过RAID卡读取SMART smartctl -a -d megaraid,21 /dev/bus/8 # /dev/bus/8对应smartctl --scan扫描的megaraid设备 # 主要关注Health Status, Temperature以及Error等指标 # 自动扫描所有硬盘 for i in {21..34}; do smartctl -a -d megaraid,$i /dev/bus/8 |egrep "Health Status|Current Drive Temperature"" done # 设置邮件报警(需要服务器联网,且配置好了mailx) #!/bin/bash # 因为是2组RAID5,所以用了/vall,且都是正常应该2组的State都是Optl if [ `/opt/MegaRAID/storcli/storcli64 /c0 /vall show |grep RAID5 |grep -c Optl` != 2 ]; then echo "RAID 阵列异常!状态:$(/opt/MegaRAID/storcli/storcli64 /c0 /vall show |grep RAID5 |awk '{print $1 "," $3}' |paste -d';' -s)" | mail -s "RAID 告警" 315940882@qq.com fi
硬RAID阵列故障处理¶
硬RAID阵列故障分为磁盘故障和RAID卡故障,磁盘故障较为常见。
假如是/c0/e20/s10这块盘坏了,现需要替换同样大小容量硬盘进行更换并恢复阵列。
-
确认故障硬盘状态
首先检查阵列状态,确认/c0/e20/s10是否标记为Failed或Offline/opt/MegaRAID/storcli/storcli64 /c0/e20/s10 show /opt/MegaRAID/storcli/storcli64 /c0/v1 show # /c0/e20/s10在上面拓扑表格中对应的DG为1,所以这里是v1 # 如果硬盘尚未被RAID卡自动标记为故障,手动标记为离线 /opt/MegaRAID/storcli/storcli64 /c0/e20/s10 set offline -
物理更换硬盘
故障硬盘标记为Offline后,硬盘灯变为黄色/琥珀色,从此硬盘槽位抽出故障硬盘,然后在此槽位插入同样品牌同样大小容量的新硬盘。
如果没看到黄灯,也可触发故障盘定位灯闪烁(蓝色/白色闪烁状态)来定位故障硬盘的硬盘槽位。# 启动定位模式(闪烁) /opt/MegaRAID/storcli/storcli64 /c0/e20/s10 start locate # 停止定位模式 /opt/MegaRAID/storcli/storcli64 /c0/e20/s10 stop locate -
检查新硬盘是否被识别
等待RAID卡检测新硬盘(通常几秒到几分钟),然后验证输出中检查: State应为Unconfigured(good)或JBOD(表示新硬盘已就绪),Firmware状态无错误提示。/opt/MegaRAID/storcli/storcli64 /c0/e20/s10 show -
将新硬盘加入阵列并触发重建
如果阵列处于降级状态(Degraded),需手动将新硬盘添加到阵列中:# 方法1:直接替换原槽位硬盘(适用于同一物理位置) /opt/MegaRAID/storcli/storcli64 /c0/e20/s10 start rebuild # 方法2:如果是插入到其他槽位,比如是/c0/e20/s35 (用/opt/MegaRAID/storcli/storcli64 /c0 show查看阵列和硬盘拓扑) /opt/MegaRAID/storcli/storcli64 /c0/e20/s35 insert dg=1 array=0 row=7 # DG=1就是/v1了,之前的拓扑信息,/v1最后是Arr=0,Row=6了 -
监控重建进度
# 查看阵列重建进度 /opt/MegaRAID/storcli/storcli64 /c0/e20/s10 show rebuild # 示例输出: ---------------------------------------------------------- Drive-ID Progress% Status Estimated Time Left ---------------------------------------------------------- /c0/e20/s10 45% In progress - ---------------------------------------------------------- -
验证阵列恢复状态
重建完成后,检查阵列状态:确保State为Optimal,所有物理硬盘状态为Online。/opt/MegaRAID/storcli/storcli64 /c0/v1 show all -
RAID卡故障处理
# 检查RAID卡状态,是否有报错信息,确认的确是RAID卡的问题 /opt/MegaRAID/storcli/storcli64 show # 确认后,停止写操作防止新数据覆盖原有数据。 # 关于RAID卡与硬盘组的RAID配置的理解 # RAID卡的配置: 每个RAID控制器的内存和固件会管理自己的配置(RAID阵列、硬盘的排列和分配方式、RAID类型等)。 # 硬盘组的RAID配置: RAID卡也会在每个磁盘上存储一些元数据(磁盘属于哪个RAID阵列、RAID类型、磁盘序号等信息)。 # 因此,如果RAID卡坏了,更换同型号的RAID卡时,新卡可以通过读取磁盘的元数据来恢复硬盘组的RAID配置。 # 对于新RAID卡,磁盘的元数据就是下面说的外部配置。 # 尝试硬件级恢复,更换同一型号相同参数的RAID卡(卡插的位置,数据线、硬盘及槽位置也保持原来顺序) # 开机进入RAID卡BIOS,检查RAID配置是否检测到,如果RAID组状态显示Foreign,不要直接清除,先尝试导入。 # 进入RAID卡BIOS,选择Foreign Configuration(外部配置),选择Import(导入)。 # 确认RAID组恢复状态:如果恢复正常,RAID组状态应变为Optimal; 如果仍然显示Degraded,可能需要手动重建RAID。 # 如果不进入BIOS导入外部配置,也可以用storcli工具来导入外部配置 /opt/MegaRAID/storcli/storcli64 /c0 show # 查看是否有Foreign Configuration # 查看自动导入状态 /opt/MegaRAID/storcli/storcli64 /c0 show foreignautoimport # 如果ForeignAutoImport的Value为OFF,需要启用自动导入 /opt/MegaRAID/storcli/storcli64 /c0 set foreignautoimport=on # 如果在BIOS中外部配置导入不起作用,那么用storcli工具来导入外部配置可能也不起作用,因为两者功能是一样的。 # 如果起作用,但个别硬盘没识别到相应RAID阵列中,可以用前面更换硬盘再触发重建的方法 /opt/MegaRAID/storcli/storcli64 /c0/ex/sx start rebuild # /ex扩展器x,/sx表示磁盘槽位x # 外部配置不起作用,需要手动重建RAID # 但手动重建,需要备份的RAID配置文件,因而再建立RAID后,养成个好习惯备份RAID配置。 /opt/MegaRAID/storcli/storcli64 /c0 get config file=raid_config.cfg # 备份 /opt/MegaRAID/storcli/storcli64 /c0 set config file=raid_config.cfg # 手动重建,恢复 # 一旦RAID组恢复,建议检查文件系统数据完整性 fsck -y /dev/sdX # 如果使用ext4 xfs_repair /dev/sdX # 如果使用xfs
FastCFS文件系统搭建¶
FastCFS是一款强一致性、高性能、高可用、支持百亿级海量文件的通用分布式文件系统,可以作为MySQL、PostgreSQL、Oracle等数据库,k8s、KVM、FTP、SMB和NFS等系统的后端存储。
-
架构设计
FastCFS的架构设计旨在提供高性能和可扩展性。它采用了一种新颖的架构,充分利用并行和多核处理器的优势,从而实现高效的数据存储和访问。FastCFS的核心组件包括FastDIR和FastStore。FastDIR管理文件元数据,而FastStore则以分块方式存储文件内容。两者都采用Master/Slave结构,Master节点由程序自动选举产生,并且支持failover(故障转移)。 -
数据存储机制
FastCFS采用数据分组的做法,一个数据分组的几个节点(如三个节点即三副本)之间是Master/Slave关系。更新操作只能由Master处理,然后Master同步调用Slave转发该请求。为了确保数据强一致,FastCFS通过Master/Slave结构的同步复制机制来保证数据一致性。当Slave因重启服务或网络通信异常导致掉线时,OFFLINE状态的Slave会进入数据恢复阶段,追上Master的最新数据后,方可切换为ACTIVE状态。 -
同步复制机制
FastCFS的同步复制机制通过Master/Slave结构来实现数据强一致。client的更新操作只能由Master处理,然后Master同步调用Slave转发该请求。为了确保平滑切换,FastCFS引入了leader/follower机制来维护精准的集群状态。Leader通过选举产生,Follower和Leader建立连接并每秒报告其自身状态(如磁盘空间、数据版本号等)。当集群状态发生变化时,Leader会立即将变动消息推送给所有Follower。 -
分布式存储优势
FastCFS作为一个分布式文件系统,解决了传统文件存储架构中图片存储过于分散、I/O操作性能低等问题。它通过搭建专门的图片服务器来处理图片存储和访问,充分利用并行和多核处理器的优势,提供高效的数据存储和访问。此外,FastCFS还支持文件同步和负载均衡,进一步提升了系统的整体性能和可靠性。
FastCFS安装¶
FastCFS支持分布式存储,但考虑到成本原因,只用到单节点副本,数据冗余采用RAID阵列。
采购的IB存储节点做FastCFS的服务端节点(hostname: ibnas; IP: 11.1.255.254)
集群管理节点(hostname: quantum; IP: 11.1.255.253)和所有计算节点作为FastCFS的客户端。
IB存储节点上硬盘格式化、分区及挂载
[root@ibnas ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 43.7T 0 disk
└─sda1 8:1 0 43.7T 0 part /opt/faststore/data/raid5_01
sdb 8:16 0 43.7T 0 disk
└─sdb1 8:17 0 43.7T 0 part /opt/faststore/data/raid5_02
nvme1n1 259:0 0 3.7T 0 disk
└─nvme1n1p1 259:1 0 3.7T 0 part /opt/fastcfs/fstore
nvme3n1 259:2 0 349.3G 0 disk
└─nvme3n1p1 259:3 0 349.3G 0 part
└─md0 9:0 0 698.4G 0 raid0 /opt/fastcfs/fdir
nvme2n1 259:4 0 349.3G 0 disk
└─nvme2n1p1 259:5 0 349.3G 0 part
└─md0 9:0 0 698.4G 0 raid0 /opt/fastcfs/fdir
nvme0n1 259:6 0 465.8G 0 disk
├─nvme0n1p1 259:7 0 1G 0 part /boot
├─nvme0n1p2 259:8 0 512M 0 part /boot/efi
└─nvme0n1p3 259:9 0 464.3G 0 part
├─rl-root 253:0 0 460.3G 0 lvm /
└─rl-swap 253:1 0 4G 0 lvm [SWAP]
-
安装yum源
所有节点的系统都是Rocky Linux 8.10,管理节点和IB存储节点能连接外网,计算节点与管理节点和IB存储节点是局域网。
在能联网的管理节点和IB存储节点上执行:在管理节点上为计算节点构建本地yum源rpm -ivh http://www.fastken.com/yumrepo/el8/noarch/FastOSrepo-1.0.1-1.el8.noarch.rpmmkdir -p /var/www/html/FastOS/Packages cd /var/www/html/FastOS/Packages wget http://www.fastken.com/yumrepo/el8/x86_64/FastCFS-api-libs-5.3.3-1.el8.x86_64.rpm wget http://www.fastken.com/yumrepo/el8/x86_64/FastCFS-auth-client-5.3.3-1.el8.x86_64.rpm wget http://www.fastken.com/yumrepo/el8/x86_64/FastCFS-auth-config-5.3.3-1.el8.x86_64.rpm wget http://www.fastken.com/yumrepo/el8/x86_64/FastCFS-fuse-config-5.3.3-1.el8.x86_64.rpm wget http://www.fastken.com/yumrepo/el8/x86_64/FastCFS-fused-5.3.3-1.el8.x86_64.rpm wget http://www.fastken.com/yumrepo/el8/x86_64/FastCFS-vote-client-5.3.3-1.el8.x86_64.rpm wget http://www.fastken.com/yumrepo/el8/x86_64/FastCFS-vote-config-5.3.3-1.el8.x86_64.rpm wget http://www.fastken.com/yumrepo/el8/x86_64/fastDIR-client-5.3.3-1.el8.x86_64.rpm wget http://www.fastken.com/yumrepo/el8/x86_64/fastDIR-config-5.3.3-1.el8.x86_64.rpm wget http://www.fastken.com/yumrepo/el8/x86_64/fastDIR-server-5.3.3-1.el8.x86_64.rpm wget http://www.fastken.com/yumrepo/el8/x86_64/faststore-client-5.3.3-2.el8.x86_64.rpm wget http://www.fastken.com/yumrepo/el8/x86_64/faststore-config-5.3.3-2.el8.x86_64.rpm wget http://www.fastken.com/yumrepo/el8/x86_64/faststore-server-5.3.3-1.el8.x86_64.rpm wget http://www.fastken.com/yumrepo/el8/x86_64/fuse3-3.10.5-1.el8.x86_64.rpm wget http://www.fastken.com/yumrepo/el8/x86_64/fuse3-libs-3.10.5-1.el8.x86_64.rpm wget http://www.fastken.com/yumrepo/el8/x86_64/fuse-common-3.10.5-1.el8.x86_64.rpm wget http://www.fastken.com/yumrepo/el8/x86_64/libdiskallocator-1.1.10-1.el8.x86_64.rpm wget http://www.fastken.com/yumrepo/el8/x86_64/libfastcommon-1.0.76-1.el8.x86_64.rpm wget http://www.fastken.com/yumrepo/el8/x86_64/libfastcommon-debuginfo-1.0.76-1.el8.x86_64.rpm wget http://www.fastken.com/yumrepo/el8/x86_64/libfastrdma-1.0.5-1.el8.x86_64.rpm wget http://www.fastken.com/yumrepo/el8/x86_64/libfdirstorage-1.1.9-3.el8.x86_64.rpm wget http://www.fastken.com/yumrepo/el8/x86_64/libfsstorage-1.1.9-4.el8.x86_64.rpm wget http://www.fastken.com/yumrepo/el8/x86_64/libserverframe-1.2.6-3.el8.x86_64.rpm createrepo /var/www/html/FastOS/ -
IB存储节点安装FastStore和FastDIR
yum install fastDIR-server faststore-server -y -
安装客户端
yum remove fuse -y // 仅第一次安装时执行 yum install FastCFS-fused -y
FastCFS配置文件¶
FastCFS并没有统一的配置中心,需要在各个节点上都部署配置文件:集群配置文件cluster.conf,服务配置文件server.conf,还有fused服务配置文件fuse.conf。
/etc/fastcfs/
|
|__ fcfs: fused服务
| |__ fuse.conf: fcfs_fused对应的配置文件
|
|__ fdir: FastDIR目录服务
| |__ cluster.conf: 服务器列表,配置服务器ID、IP和端口
| |__ server.conf: fdir_serverd对应的配置文件
| |__ storage.conf: 持久化存储配置文件
| |__ client.conf: 客户端配置文件
|
|__ fstore: faststore存储服务
|__ cluster.conf: 服务器列表(配置服务器ID、IP和端口),并配置服务器分组及数据分组之间的对应关系
|__ storage.conf: 存储路径及空间分配和回收配置
|__ server.conf: fs_serverd对应的配置文件
|__ client.conf: 客户端配置文件
-
修改配置文件
/etc/fastcfs/fdir/cluster.conf## 其他内容用默认的即可,主要修改通讯用rdma网络, ## 还有就是修改服务端IP # the communication value list: ## socket: TCP over ethernet or RDMA network ## rdma: RDMA network only communication = rdma ## Important:server group mark, don't modify this line. # config a server instance # the section format: [server-$sid] # $sid as the server id is a 32 bits natural number (1, 2, 3 etc.), can be discrete [server-1] # format: host[:port] # host can be an IP address or a hostname, IPv6 is supported # IP address is recommended, can occur more than once host = 11.1.255.254/etc/fastcfs/fstore/cluster.confserver.conf指的是服务本身的配置文件,设定的参数包含线程数量、链接数量、缓冲区大小、日志配置等。server.conf可以全局不统一。不过从集群的角度考虑,如果各服务器配置相同,最好是统一的。## 同样其他内容用默认的即可,主要修改通讯用rdma网络, ## 还有就是修改服务端IP # the communication value list: ## socket: TCP over ethernet or RDMA network ## rdma: RDMA network only communication = rdma ## Important:server group mark, don't modify this line. # config a server # the section format: [server-$sid] # $sid as the server id is a 32 bits natural number (1, 2, 3 etc.), can be discrete [server-1] # format: host[:port] # host can be an IP address or a hostname, IPv6 is supported # IP address is recommended, can occur more than once host = 11.1.255.254
fdir和fstore的server.conf内容保持默认就行,除非是想修改binlog和log日志文件的存储路径,之前我们分别用SSD挂载了/opt/fastcfs/fdir和/opt/fastcfs/fstore做默认存储路径就行。
我们要把存储池作为共享存储,所以需要修改Client自身的配置文件fuse.conf/etc/fastcfs/fcfs/fuse.conf在管理节点修改好这些配置文件,再用pdcp并行远程命令批处理拷贝# the base path to store log files # this path must exist #base_path = /opt/fastcfs/fcfs base_path = /fastcfs/fcfs # the mount point (local path) for FUSE # the local path must exist #mountpoint = /opt/fastcfs/fuse mountpoint = /datapool # if use busy polling for RDMA network # should set to true for HPC # default value is false #busy_polling = false busy_polling = true [FastDIR] # 对于文件追加写或文件truncate操作,通过加锁避免冲突 # if use sys lock for file append and truncate to avoid conflict # set true when the files appended or truncated by many nodes (FUSE instances) # default value is false #use_sys_lock_for_append = false use_sys_lock_for_append = true # 禁用异步报告文件属性(即采用同步报告方式) # if async report file attributes (size, modify time etc.) to the FastDIR server # default value is true #async_report_enabled = true async_report_enabled = false [write-combine] # 禁用合并写 # if enable write combine feature for FastStore # default value is true #enabled = true enabled = false [read-ahead] # 禁用预读机制 # if enable read ahead feature for FastStore # default value is true #enabled = true enabled = false [FUSE] # 禁用Linux对inode缓存 # cache time for file attribute in seconds # default value is 1.0s #attribute_timeout = 5.0 attribute_timeout = 0.1 # 禁用Linux对文件属性缓存 # cache time for file entry in seconds # default value is 1.0s #entry_timeout = 5.0 entry_timeout = 0.1 # 禁用内核合并写 # if enable kernel writeback cache # set to true for unshared data scene (private data for single node) # default value is true #writeback_cache = true writeback_cache = false # 禁用内核读缓存 # if keep kernel cache for read # set to true for unshared data scene (private data for single node) # should set to false on shared data scene for multi nodes # default value is true #kernel_cache = true kernel_cache = falsepdcp -a /etc/fastcfs/fstore/cluster.conf /etc/fastcfs/fstore/cluster.conf pdcp -a /etc/fastcfs/fdir/cluster.conf /etc/fastcfs/fdir/cluster.conf pdcp -a /etc/fastcfs/fcfs/fuse.conf /etc/fastcfs/fcfs/fuse.conf -
磁盘数据路径配置
磁盘作为数据存储,在IB存储节点中的faststore中作为永久存储,在storage.conf中配置/etc/fastcfs/fstore/storage.conf# the write thread count per store path # the default value is 1 write_threads_per_path = 6 # the read thread count per store path # the default value is 1 read_threads_per_path = 6 # usually one store path for one disk to store user files # each store path is configurated in the section as: [store-path-$id], # eg. [store-path-1] for the first store path, [store-path-2] for # the second store path, and so on. store_path_count = 2 # reserved space of each disk for system or other applications. # the value format is XX% # the default value is 10% reserved_space_per_disk = 10% #### store paths config ##### [store-path-1] # the path to store user files path = /opt/faststore/data/raid5_01 [store-path-2] path = /opt/faststore/data/raid5_02 -
启动服务
先在IB存储节点重启fastdir服务,再重启faststore服务若FastCFS服务端fastdir服务和faststore服务启动没问题,就可以启动客户端的fastcfs服务[root@ibnas ~]# systemctl restart fastdir # 重启后,用systemctl status fastdir查看启动成功没 # 如果没成功,查看/opt/fastcfs/fdir/logs/fdir_serverd.log [root@ibnas ~]# systemctl restart faststore # 重启后,用systemctl status faststore查看启动成功没 # 如果没成功,查看/opt/fastcfs/fstore/logs/fs_serverd.logfastcfs启动没问题,再用# 重启服务前,需要建立挂载点,配置文件中我们想挂载为/datapool [root@quantum ~]# mkdir -p /datapool # fuse.conf中修改了存储日志文件路径,也需要先建立路径 [root@quantum ~]# mkdir -p /fastcfs/fcfs [root@quantum ~]# systemctl restart fastcfs # 重启后,用systemctl status fastcfs查看启动成功没 # 如果没成功,查看/fastcfs/fcfs/logs/fcfs_fused.logdf -hl查看存储池是否挂载上。没问题后,用pdsh并行远程命令在计算节点批处理执行[root@quantum ~]# df -hl |grep datapool /dev/fuse 78T 6.9T 72T 9% /datapool[root@quantum ~]# pdsh -a mkdir -p /datapool [root@quantum ~]# pdsh -a mkdir -p /fastcfs/fcfs [root@quantum ~]# pdsh -a systemctl restart fastcfs # 验证/datapool是否挂载成功 [root@quantum ~]# pdsh -a df -hl |grep datapool
性能测试及调优¶
-
测试连续拷贝大文件速度
不管怎么拷贝,大文件持续拷贝速度在450-460 MB/s。rsync本身是单线程,且受限于源文件所在硬盘的读取速度。# 现在把客户端11.1.255.253的一块Intel U.2 SSD上的10GB左右的ISO镜像拷贝到组建的/datapool数据池中 [root@quantum datapool]# rsync -r /opt/temp/Rocky-8.8-custom-hpc.iso ./ --info=progress2 12,772,030,464 100% 460.96MB/s 0:00:26 (xfr#1, to-chk=0/1) # 把客户端的镜像文件拷贝到存储节点的系统nvme SSD的/tmp目录下 [root@ibnas tmp]# rsync -r root@11.1.255.253:/opt/temp/Rocky-8.8-custom-hpc.iso ./ --info=progress2 12,772,030,464 100% 456.84MB/s 0:00:26 (xfr#1, to-chk=0/1) # 把客户端的镜像文件拷贝到存储节点的傲腾SSD上 [root@ibnas fdir]# rsync -r root@11.1.255.253:/opt/temp/Rocky-8.8-custom-hpc.iso ./ --info=progress2 12,772,030,464 100% 452.53MB/s 0:00:26 (xfr#1, to-chk=0/1) # 把客户端的镜像文件拷贝到存储节点的西部数据PCIe 3.0x8 NVME SSD上 [root@ibnas fstore]# rsync -r root@11.1.255.253:/opt/temp/Rocky-8.8-custom-hpc.iso ./ --info=progress2 12,772,030,464 100% 454.00MB/s 0:00:26 (xfr#1, to-chk=0/1) # 把客户端的镜像文件拷贝到存储节点的SAS RAID5 阵列上 [root@ibnas raid5_02]# rsync -r root@11.1.255.253:/opt/temp/Rocky-8.8-custom-hpc.iso ./ --info=progress2 12,772,030,464 100% 455.99MB/s 0:00:26 (xfr#1, to-chk=0/1)
目前只能说明存储池和RAID阵列在大文件持续传输上跟NVME U.2 SSD性能差不多。具体的性能测试还需要用fio工具测试。 -
fio性能测试
随机I/O主要关注IOPS,顺序I/O主要关注带宽(MB/s)。从上面的测试结果可看出:硬RAID阵列的顺序和随机写能力都很差,而FastCFS利用SSD固态硬盘做FastDIR和FastStore核心组件可加速HDD磁盘存储路径的读写性能。多线程顺序写入差不多也能接近56Gbps InfiniBand网速了。## 测试RAID 5阵列的读写性能 [root@ibnas raid5_02]# fio --name=seq_write --rw=write --bs=1M --size=1G --numjobs=5 --direct=1 --ioengine=libaio --iodepth=32 --output=fio_seqwrite_1G_1M.txt # 其中, --direct=1: 绕过缓存(直写到存储设备); --ioengine=libaio: 使用Linux AIO(异步I/O); --iodepth=32: 设置队列深度为32 Run status group 0 (all jobs): WRITE: bw=710MiB/s (744MB/s), 142MiB/s-146MiB/s (149MB/s-153MB/s), io=5120MiB (5369MB), run=7034-7214msec # RAID 5阵列的单线程顺序写入速度是150 MB/s,5线程合计写入带宽744 MB/s [root@ibnas raid5_02]# fio --name=seq_read --rw=read --bs=1M --size=1G --numjobs=5 --direct=1 --ioengine=libaio --iodepth=32 --output=fio_seqread_1G_1M.txt Run status group 0 (all jobs): READ: bw=1380MiB/s (1447MB/s), 276MiB/s-600MiB/s (289MB/s-629MB/s), io=5120MiB (5369MB), run=1706-3710msec # RAID 5阵列的单线程顺序读取速度是289-629 MB/s,5线程合计读取带宽1447 MB/s [root@ibnas raid5_02]# fio --name=rand_write --rw=randwrite --bs=4K --size=1G --numjobs=5 --direct=1 --ioengine=libaio --iodepth=32 --output=fio_randwrite_1G_4K.txt rand_write: (groupid=0, jobs=1): IOPS=193, BW=775KiB/s (793kB/s)(1024MiB/1353623msec) Run status group 0 (all jobs): WRITE: bw=3834KiB/s (3926kB/s), 767KiB/s-775KiB/s (785kB/s-793kB/s), io=5120MiB (5369MB), run=1353623-1367489msec # RAID 5阵列的单线程随机写入IOPS是193,5线程合计随机写入IOPS为965,可看出随机写性能较低。 # RAID 5需要计算奇偶校验,每次写入都会涉及"读-改-写"操作,导致额外开销; # 机械硬盘的随机写性能低,通常只有几百IOPS。 [root@ibnas raid5_02]# fio --name=rand_read --rw=randread --bs=4K --size=1G --numjobs=5 --direct=1 --ioengine=libaio --iodepth=32 --output=fio_randread_1G_4K.txt rand_read: IOPS=1025-1572,BW=4103-6288KiB/s (4201-6439kB/s) Run status group 0 (all jobs): READ: bw=20.0MiB/s (21.0MB/s), 4103KiB/s-6288KiB/s (4201kB/s-6439kB/s), io=5120MiB (5369MB), run=166756-255563msec # RAID 5阵列的单线程单线程随机读取IOPS是1025-1572,5线程合计随机读取IOPS为5125-7860 ## 测试2块傲腾SSD组的软RAID 0阵列的读写性能 [root@ibnas fdir]# fio --name=seq_write --rw=write --bs=1M --size=1G --numjobs=5 --direct=1 --ioengine=libaio --iodepth=32 --output=fio_seqwrite_1G_1M.txt Run status group 0 (all jobs): WRITE: bw=4380MiB/s (4593MB/s), 876MiB/s-877MiB/s (919MB/s-919MB/s), io=5120MiB (5369MB), run=1168-1169msec # 傲腾软RAID 0阵列的单线程顺序写入速度是919 MB/s,5线程合计写入带宽4593 MB/s [root@ibnas fdir]# fio --name=seq_read --rw=read --bs=1M --size=1G --numjobs=5 --direct=1 --ioengine=libaio --iodepth=32 --output=fio_seqread_1G_1M.txt Run status group 0 (all jobs): READ: bw=5151MiB/s (5401MB/s), 1030MiB/s-1082MiB/s (1080MB/s-1135MB/s), io=5120MiB (5369MB), run=946-994msec # 傲腾软RAID 0阵列的单线程顺序读取速度是1080-1135 MB/s,5线程合计读取带宽5401 MB/s [root@ibnas fdir]# fio --name=rand_write --rw=randwrite --bs=4K --size=1G --numjobs=5 --direct=1 --ioengine=libaio --iodepth=32 --output=fio_randwrite_1G_4K.txt rand_write: (groupid=0, jobs=1): IOPS=94.9k, BW=371MiB/s (389MB/s)(1024MiB/2762msec) Run status group 0 (all jobs): WRITE: bw=1825MiB/s (1914MB/s), 365MiB/s-372MiB/s (383MB/s-390MB/s), io=5120MiB (5369MB), run=2750-2805msec # 傲腾软RAID 0阵列的单线程随机写入IOPS是94.9k,5线程合计随机写入IOPS为474.5k [root@ibnas fdir]# fio --name=rand_read --rw=randread --bs=4K --size=1G --numjobs=5 --direct=1 --ioengine=libaio --iodepth=32 --output=fio_randread_1G_4K.txt rand_read: (groupid=0, jobs=1): IOPS=187.4k, BW=733MiB/s (769MB/s)(1024MiB/1397msec) Run status group 0 (all jobs): READ: bw=3462MiB/s (3630MB/s), 692MiB/s-760MiB/s (726MB/s-797MB/s), io=5120MiB (5369MB), run=1347-1479msec # 傲腾软RAID 0阵列的单线程随机读取IOPS是187.4k,5线程合计随机读取IOPS为937.0k ## 西部数据PCIe 3.0x8 NVME SSD的读写性能 [root@ibnas fstore]# fio --name=seq_write --rw=write --bs=1M --size=1G --numjobs=5 --direct=1 --ioengine=libaio --iodepth=32 --output=fio_seqwrite_1G_1M.txt Run status group 0 (all jobs): WRITE: bw=4070MiB/s (4268MB/s), 814MiB/s-884MiB/s (854MB/s-927MB/s), io=5120MiB (5369MB), run=1158-1258msec # 西部数据PCIe 3.0x8 NVME SSD的单线程顺序写入速度是854-927 MB/s,5线程合计写入带宽4268 MB/s [root@ibnas fstore]# fio --name=seq_read --rw=read --bs=1M --size=1G --numjobs=5 --direct=1 --ioengine=libaio --iodepth=32 --output=fio_seqread_1G_1M.txt Run status group 0 (all jobs): READ: bw=5476MiB/s (5742MB/s), 1095MiB/s-2306MiB/s (1148MB/s-2418MB/s), io=5120MiB (5369MB), run=444-935msec # 西部数据PCIe 3.0x8 NVME SSD的单线程顺序读取速度是1095-2306 MB/s,5线程合计读取带宽5742 MB/s [root@ibnas fstore]# fio --name=rand_write --rw=randwrite --bs=4K --size=1G --numjobs=5 --direct=1 --ioengine=libaio --iodepth=32 --output=fio_randwrite_1G_4K.txt rand_write: IOPS=35.4k - 122k, BW=138MiB/s - 477MiB/s (145MB/s - 500MB/s)(1024MiB/7399msec - 1024MiB/2146msec) Run status group 0 (all jobs): WRITE: bw=692MiB/s (725MB/s), 138MiB/s-477MiB/s (145MB/s-500MB/s), io=5120MiB (5369MB), run=2146-7401msec # 西部数据PCIe 3.0x8 NVME SSD的单线程随机写入IOPS是35.4-122k,5线程合计随机写入IOPS为264k [root@ibnas fstore]# fio --name=rand_read --rw=randread --bs=4K --size=1G --numjobs=5 --direct=1 --ioengine=libaio --iodepth=32 --output=fio_randread_1G_4K.txt rand_read: IOPS=160k - 178k, BW=626MiB/s - 695MiB/s (657MB/s - 728MB/s)(1024MiB/1635msec - 1024MiB/1474msec) Run status group 0 (all jobs): READ: bw=3131MiB/s (3284MB/s), 626MiB/s-695MiB/s (657MB/s-728MB/s), io=5120MiB (5369MB), run=1474-1635msec # 西部数据PCIe 3.0x8 NVME SSD的单线程随机读取IOPS是160-178k,5线程合计随机读取IOPS为841k ## 测试FastCFS挂载存储的读写性能 [root@quantum datapool]# fio --name=seq_write --rw=write --bs=1M --size=1G --numjobs=5 --direct=1 --ioengine=libaio --iodepth=32 --output=fio_seqwrite_1G_1M.txt Run status group 0 (all jobs): WRITE: bw=6059MiB/s (6354MB/s), 1212MiB/s-1218MiB/s (1271MB/s-1277MB/s), io=5120MiB (5369MB), run=841-845msec # FastCFS挂载存储的单线程顺序写入速度是1271 MB/s,5线程合计写入带宽6354 MB/s [root@quantum datapool]# fio --name=seq_read --rw=read --bs=1M --size=1G --numjobs=5 --direct=1 --ioengine=libaio --iodepth=32 --output=fio_seqread_1G_1M.txt Run status group 0 (all jobs): READ: bw=6169MiB/s (6468MB/s), 1234MiB/s-1240MiB/s (1294MB/s-1300MB/s), io=5120MiB (5369MB), run=826-830msec # FastCFS挂载存储的单线程顺序读取速度是1294 MB/s,5线程合计读取带宽6468 MB/s [root@quantum datapool]# fio --name=rand_write --rw=randwrite --bs=4K --size=1G --numjobs=5 --direct=1 --ioengine=libaio --iodepth=32 --output=fio_randwrite_1G_4K.txt rand_write: (groupid=0, jobs=1): IOPS=16.9k, BW=65.9MiB/s (69.1MB/s)(1024MiB/15548msec) Run status group 0 (all jobs): WRITE: bw=329MiB/s (345MB/s), 65.8MiB/s-65.9MiB/s (69.0MB/s-69.1MB/s), io=5120MiB (5369MB), run=15529-15561msec # FastCFS挂载存储的单线程随机写入IOPS是16.9k,5线程合计随机写入IOPS为84.5k [root@quantum datapool]# fio --name=rand_read --rw=randread --bs=4K --size=1G --numjobs=5 --direct=1 --ioengine=libaio --iodepth=32 --output=fio_randread_1G_4K.txt rand_read: (groupid=0, jobs=1): IOPS=18.8k, BW=73.4MiB/s (76.0MB/s)(1024MiB/13953msec) Run status group 0 (all jobs): READ: bw=367MiB/s (385MB/s), 73.3MiB/s-73.5MiB/s (76.9MB/s-77.1MB/s), io=5120MiB (5369MB), run=13931-13961msec # FastCFS挂载存储的单线程随机读取IOPS是18.8k,5线程合计随机读取IOPS为94.0k -
性能调优(有待测试)
- RAID 5阵列由于奇偶校验导致的额外写放大问题,不用硬RAID,直接把每个磁盘都作为FastCFS的磁盘存储路径。但FastCFS不支持单节点数据冗余(多副本是支持的),这样数据安全有风险。
- 如果实在要用硬RAID卡,也可做优化。硬RAID卡接超级电容BBU(就是卡上加电池),开启Write-Back模式,卡缓存加速异步写入。如果RAID卡支持SSD作为缓存(SSD要直接连接在RAID作为管理,其他PCIE和主板上的NVME插槽的SSD是不能的),这种CacheCade策略可降低HDD的写入延迟,提高随机IOPS,但成本也会增加。
- 使用纯OpenZFS方案,可避免RAID 5的写入放大。ZFS采用写时复制(COW)方式直接写入新数据,而不会像RAID 5那样每次都需要计算和更新奇偶校验,减少了"读-改-写"过程。即使HDD性能相同,ZFS RAID-Z2也比RAID 5适合随机小文件写入。SLog同步写入优化,L2ARC直接缓存RAID-Z2的数据,这些对于随机读性能提升也很明显。
- 调整FastCFS的FastStore组件中storage.conf配置文件的涉及线程数、IO模式、队列深度和缓存设置来提升存储池的读写能力。
# the write thread count per store path # the default value is 1 write_threads_per_path = 6 // RAID5的并发写入能力依赖控制器性能,增加线程数可提升并行度。 # the read thread count per store path # the default value is 1 read_threads_per_path = 6 // RAID5读取性能较好,多线程可充分利用并发。 # usually one store path for one disk to store user files # each store path is configurated in the section as: [store-path-$id], # eg. [store-path-1] for the first store path, [store-path-2] for # the second store path, and so on. store_path_count = 2 # the trunk files are used for striped disk space management # the trunk file size from 64MB to 1GB, the default value is 256MB trunk_file_size = 512MB // 增大Trunk文件减少碎片,适配RAID5大块顺序写入优势。 # reserved space of each disk for system or other applications. # the value format is XX%, the default value is 10% reserved_space_per_disk = 10% # trunk pre-allocate thread count # these threads for pre-allocate or reclaim trunks when necessary # the default value is 1 trunk_allocator_threads = 4 // 增加回收线程,加快大容量RAID5的回收速度。 #### store paths config ##### [store-path-1] # the path to store user files path = /opt/faststore/data/raid5_01 write_threads = 6 // 如果设置将覆盖前面的全局变量write_threads_per_path read_threads = 6 // 如果设置将覆盖前面的全局变量read_threads_per_path write_direct_io = true // 需要raid卡添加超级电容BBU,并设置Write-Back模式 read_direct_io = false // 读取时利用系统缓存可提升随机读性能,RAID5随机读性能尚可。保持false。 read_io_depth = 32 // RAID5机械盘IOPS较低,队列深度过高会增加延迟,保持适中即可。但是测试对比32和64,性能差不多,默认64也行。 fsync_every_n_writes = 2000 // 减少fsync调用频率(默认是0,不调用),降低写入延迟,但需权衡数据安全性。 [store-path-2] path = /opt/faststore/data/raid5_02 write_threads = 6 // 如果设置将覆盖前面的全局变量write_threads_per_path read_threads = 6 // 如果设置将覆盖前面的全局变量read_threads_per_path write_direct_io = true // 需要raid卡添加超级电容BBU,并设置Write-Back模式 read_direct_io = false // 读取时利用系统缓存可提升随机读性能,RAID5随机读性能尚可。保持false。 read_io_depth = 32 // RAID5机械盘IOPS较低,队列深度过高会增加延迟,保持适中即可。但是测试对比32和64,性能差不多,默认64也行。 fsync_every_n_writes = 2000 // 减少fsync调用频率(默认是0,不调用),降低写入延迟,但需权衡数据安全性。
- RAID 5阵列由于奇偶校验导致的额外写放大问题,不用硬RAID,直接把每个磁盘都作为FastCFS的磁盘存储路径。但FastCFS不支持单节点数据冗余(多副本是支持的),这样数据安全有风险。
FastCFS使用中遇到的问题¶
-
Fused挂载家目录存储,在其他节点执行命令用|tee log这种追加操作,在其他节点查看这个log文件,内容大小不一致。
对于共享存储,追加写操作需要按照共享数据配置指南进行配置。当然对于禁用文件缓存、内核合并写、内核读缓存,文件系统的性能有一定程度降低。 -
FastCFS 5.3.2版本的RDMA时,ssh到CPU负载稍高的节点就很慢,而且提交mpich编译的程序作业时,客户端节点fused挂载的存储容易掉线。
这个其实是thread local性能优化的bug,暂时换用socket通讯。与作者余庆老师联系,修复bug,更新到5.3.3解决问题。 -
编译安装mpich-4.0.3时出现"Too many open files"的错误。
在/etc/security/limits.conf里加入重新ssh进入,编译安装仍然出现同样的错误。使用* soft nofile 65535 * hard nofile 65535 #下面两行添加core作为调试coredump * soft core unlimited * hard core unlimitedcat /proc/$(pidof fcfs_fused)/limits查看发现nofile限制没生效。
应该是systemd的问题,做如下操作重启服务后,再使用sed -i '/Type=forking/a LimitNOFILE=65535' /usr/lib/systemd/system/fastcfs.service sed -i '/Type=forking/a LimitCORE=infinity' /usr/lib/systemd/system/fastcfs.service systemctl daemon-reload systemctl restart fastcfs.servicecat /proc/$(pidof fcfs_fused)/limits验证限制是否起作用。 -
在/etc/fastcfs/fstore/storage.conf中配置了2个存储路径,它们的存储占用空间不一致,如下:
此外,这两个存储路径都占用9TB空间,为啥/dev/fuse才6.9TB呢,使用[root@ibnas ~]# df -hl |egrep 'raid5|fuse' /dev/sdb1 44T 9.3T 35T 22% /opt/faststore/data/raid5_02 /dev/sda1 44T 9.8T 34T 23% /opt/faststore/data/raid5_01 /dev/fuse 78T 6.9T 72T 9% /datapooldu -sh /datapool又的确是6.9TB。
Reply: 1)faststore是基于trunk file来分配空间的,trunk file会有预分配机制。
2)FastCFS基于trunk file进行空间分配,目前trunk file只会增加而不会释放。当存储路径磁盘使用率超过50%时会触发trunk文件回收。 -
在安装客户端时,执行
yum remove fuse -y会删除Gnome桌面的一些组件,导致计算节点VNC远程桌面不能使用。 FastOS仓库提供的use-common3.10.5版本与系统默认版本有冲突,与余老师联系后,他们重新梳理依赖再打包,安装新提供的rpm包,再安装之前删除的Gnome桌面组件包即可。fuse-common降级成系统默认的了,而且fuse-2.9.7和fuse3-3.10.5是共存的。这么处理,不影响正在运行的fcfs_fused,fused挂载的存储池也不会掉。mkdir -p /opt/temp/fastcfs/rpm cd /opt/temp/fastcfs/rpm wget http://www.fastken.com/yumrepo/el8/x86_64/fuse3-3.10.5-2.el8.x86_64.rpm wget http://www.fastken.com/yumrepo/el8/x86_64/fuse3-libs-3.10.5-2.el8.x86_64.rpm wget http://www.fastken.com/yumrepo/el8/x86_64/fuse-common-3.10.5-2.el8.x86_64.rpm rpm -Uvh fuse*.rpm yum install gnome-shell -y
如果是全新安装客户端FastCFS-fused,第一次也不需要执行yum remove fuse -y。
特别感谢FastCFS作者余庆老师在安装和使用FastCFS过程中给予的指导和帮助,特别是大年初一还帮忙解决问题。
反思¶
总的来说还是经验不够,主要体现在:
-
硬件参数选配还是有点不合理:
- 最开始CPU和主板提供的功耗不一致导致过不了BIOS自检。
- RAID卡还是没必要,RAID5提供的随机IOPS还是太低了,或者购买支持NVME的卡,但随之也会在机箱、硬盘背板以及U.2 SSD上花更多成本。
- 应该使用 AMD EPYC 7003系列CPU和支持PCIE 4.0的主板,提供更多更大的带宽。
- 在PCIE 4.0加持下,其实可以买三星990 Pro的M.2 SSD就行,可以不用买傲腾SSD。
-
测试时间还是短了,导致存储方案不是很满意,尽管在顺序写方面还好,但存储随机IOPS要稍微低点。
-
经验丰富的情况,其实SAS HDD也不用买全新的,买拆机保3年就行,成本能节省4成。
-
根据目前的使用和测试,觉得单节点存储稍满意的方案:OpenZFS + FastCFS方案。OpenZFS做RAID-Z2冗余,并用L2ARC + SLog优化性能。然后ZFS文件系统作为FasfCFS的后端存储,使用NVME 4.0 SSD作为FastDIR和FastStore进一步增强文件系统性能,且FastCFS有客户端,原生支持RDMA。
参考¶
- DIY NAS小记 | Mini高性能集群部署
- Mellanox SX6036 40G/56G IB/以太网交换机基础配置以及开启web管理
- ZFS:从10Gbps升级到40Gbps网络
- 浪潮英信服务器在BIOS中配置RAID 5的方法
- FastCFS -- 可以跑数据库的高性能通用分布式文件系统
本站总访问量 次